Emulating x86 on x64 on aarch64
This post is part of a series on retrowin32.
retrowin32, my Windows emulator can be viewed as a combination of an x86 emulator and a Windows emulator. Both of these halves are necessary to run it on the web and machines that don't have an x86 processor.
But on Apple's ARM-based Macs like M1/M2, Apple already implemented a high-quality x86 emulator that, among other techniques, makes use of undocumented processor extensions just to improve the emulation speed — see Why is Rosetta 2 fast?.
However, Rosetta only supports 64-bit x86 ("x86-64" or "x64"), so I had thought it wasn't relevant for my goal of emulating 32-bit Windows. The 64-bit x86 instruction set is an extension of 32-bit x86 but there are small differences that mean you cannot just take an executable written for a 32-bit processor and run it on a 64-bit processor.
But my impression was wrong. As a backwards compatibility thing x64 includes a so-called "compatibility mode" that is exactly for running 32-bit code. With this mode, some cooperation from the OS, and a few bits of subtlety, I was able to adapt retrowin32 to run a 32-bit Windows exe "natively" via Rosetta on my Mac M2.
In this post I describe how this works.
Wine's implementation
As background, I discovered all this was possible from a post on the wine-devel list, where they got Wine working on ARM Macs.
As described there it is quite the amazing hack! My understanding is that Wine was written where it assumes it is running directly on a 32-bit x86 and can mix its code with the underlying executable — for example, it assumes pointers are 32-bit. In that post's approach they not only modified Wine, but they also created a custom C compiler complete with language extensions that, among other things, understands that code and pointers are straddling both 32- and 64- bit worlds and which can transparently convert between them.
In retrowin32's case, I already have a fairly strong distinction between emulator code and x86 code, so I did not need a custom compiler. But the descriptions from the Wine authors was significantly helpful in my task.
By the way, when reading more about the above I learned that Ken, the author of that code, died soon after writing it. Ken, I doff my hacker hat to you.
The big picture
So you want to run a 32-bit exe on a 64-bit processor. How does it work? In broad terms, you make a 64-bit bit program that loads the 32-bit exe and jumps into its code. To make that work out there are a few main parts.
One is getting memory laid out right. The 32-bit exe thinks it's running on a 32-bit processor, which means it only addresses the first 4gb of address space and generally assumes that it can use that space. So you want to put all the 64-bit related code, data, OS support, etc. outside of that 32-bit range.
The second piece is how you switch into 32-bit compatibility mode. Some of the code in your process is 64-bit (the part above 4gb, which interacts with the OS) and some is 32-bit and you need the processor to switch modes when running the latter.
The third piece, closely related to the second, is how you call back out to the 64-bit code. At some point the 32-bit exe wants to do some OS interaction like printing to stdout or creating a window, and to do so it needs to bridge out to the 64-bit host.
The next few sections go into each of these.
Memory layout
For part one, we want to create a 64-bit executable that puts all its stuff above 4gb, reserving the lower 4gb of address space for the 32-bit exe.
An aside about the task of programming. As programmers I think of our work straddling two different worlds. One is the realm of computer science, of algorithms and timeless abstractions. The other is the realm of fiddly specific details of platforms and APIs that are annoying to discover and which become rapidly obsolete as the world churns. I find a lot of joy in the former; unfortunately this particular task touches on a decent amount of the latter.
The task of laying out a program's memory is vaguely up to the OS executable loader.
On most(?) operating systems including MacOS they create a "zero page", where they mark a block of memory starting at address 0 as inaccessible. This makes code crash when it accidentally accesses addresses near zero, typically due a mistake with a null pointer. On 64-bit MacOS they actually make the zero page cover the entire low 4gb of memory, which I imagine might help catching code that accidentally used a 32-bit pointer. What this means though is that it is actually already the case that MacOS executables are already set up to not use any of the memory in the 32-bit range because of this zero page.
Unfortunately the zero page also means that memory is inaccessible. I experimented a bit with trying to resize that page at runtime but couldn't get it to work. Instead, following Wine, there are flags to the linker to change the size of the zero page; you can see a snapshot here.
If you shrink the zero page other things will get laid out to occupy the newly available space. And even if the executable is laid out above 4gb, dynamically set up structures like MacOS malloc might claim the lower memory. So again following Wine, I created an empty executable section that occupies the lower 4gb so that nothing else attempts to use it.
Getting all this to work was embarrassingly tricky for dumb computer reasons,
like getting whitespace-separated linker flags to successfully smuggle through
Rust invoking the compiler invoking the linker. Also via experimentation I found
if my empty section is larger than 2^31 it comes out as size zero in the output
binary, blech. I'm trying to avoid learning MacOS details but I did learn that
otool -l somebinary will print the binary's section layout (like objdump -h
on Linux) including the zero page.
Switching processor modes
For part 2, we want to switch our 64-bit process into x86 "compatibility mode" to execute 32-bit code.
In the old 16-bit x86 days I used segment registers to address memory. An
address like ES:AX meant computing the address as ES << 4 | AX. In the
modern 64-bit x86 era memory is generally flat, where segment registers are just
set to 0 and we use 64-bit absolute addresses to refer to memory.
I learned that in between those periods, segment registers were given a new meaning. Because all computer science problems can be solved by introducing a layer of abstraction, segment registers were changed to instead refer to indexes into a "segment descriptor" table containing more complex data. See X86 memory segmentation for some entry points to reading more.
In practice on x64 segment descriptors are mostly the domain of the OS, not
userland software, but MacOS helpfully provides a function i386_set_ldt that
lets you create your own entries in the table. And attributes in the segment
descriptor control whether it's referring to 32-bit or 64-bit code.
Here's a picture of the layout of a segment descriptor, from section 3.4.5 of the Intel manual. The "L" flag at bit 21 is the one we care about.
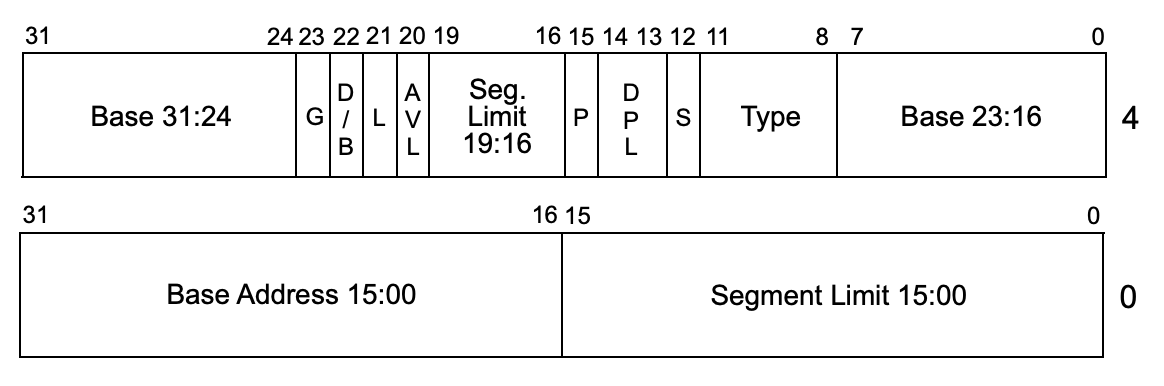
(PS: I love how the "base" address is chopped up into pieces and sprinkled into random seeming places. I believe it's because the format of this data was itself evolved over time across processor versions.)
So to get our win32 executable started, we put its code into memory, create a
segment descriptor configured to interpret that memory as 32-bit code, and use
i386_set_ldt to register that descriptor to get an index into that table which
then gives us the segment selector we can load into the CS register.
The final piece is to load that register and jump to our code. To do this there
are obscure variants of the call / jmp / ret instructions that switch both
simultaneously. See for example the last entries in
this table of the forms of call.
Emitting these particular instructions took an embarrassing amount of fiddling.
The argument to these "far" instructions is written as m16:32 in the processor
manual, which ultimately means "a pointer to memory laid out as
segment_selector << 32 | address". A segment selector is 16 bits, so the total
pointer here is 48 bits. In some places I see these "far" 48-bit pointers
referred to with syntax like CALL FWORD PTR [XXX]. I definitely muttered some
f-word pointers myself figuring this out.
I have read plenty of assembly in my time but I haven't had cause to write much, and I think these forms of these instructions are rare enough that different assemblers have different names for them, and it feels like nothing is really documented. I found myself digging through the Clang source to discover the syntaxes for these.
Calling back to 64-bit
The above is enough to transfer control to 32-bit code. At some point that 32-bit code will want to make a call out to the OS which means switching back to 64-bit code.
At a high level this looks like the process from 64-bit to 32-bit but in reverse. When you execute a far call/jmp the processor pushes the current CS segment selector and IP, and there's a corresponding far ret instruction that pops both. There are some small details (like how even in 64-bit mode a far return only pops a 32-bit IP) but it's mostly the sort of details you already need to keep in mind when working in assembly.
One detail is that the functions we ultimately want to execute are in our 64-bit code, which we above were careful to load outside of the low 4gb range. But the far call operation can only call to 32-bit address. This means that calls take multiple steps:
- Starting from the verbatim code from the exe: it contains a 32-bit regular call to our function.
- That function is 32-bit code which does a far call to switch to 64-bit mode to another function that we installed in the lower 4gb range.
- That function is 64-bit code which can then execute a call to a 64-bit address.
(One idea I'm considering is instead putting my 64-bit code at a "high" but not outside of 4gb range address, to eliminate the intermediate step. I think on win32, addresses in the 2-4gb range were reserved for the kernel so maybe I could load there, not sure.)
One additional consideration is the difference in calling conventions between
these platforms. The calls coming from the win32 exe are Windows stdcall,
which put function arguments on the stack and which expect some registers to be
preserved by the callee. We redirect these calls to eventually reach a 64-bit
Rust extern "C" function, which take arguments via various rdi etc.
registers and which have different expectations about which registers are
preserved. In practice is that we need to be sure to back up some registers on
the stack in the code gluing the two together and also do the appropriate
stdcall cleanup on the way out.
Wrapping up
With all of that in place I now have a 64-bit x86 executable that can directly run an exe on this Mac:
$ ./target/x86_64-apple-darwin/debug/retrowin32 exe/zig_hello/hello.exe
INFO kernel32/dll/LoadLibraryA(filename:Some("kernel32.dll"))
entry point at 401000, about to jump
INFO kernel32/file/WriteFile(hFile:HFILE(f11e0102), lpBuffer:Some([48, 65, 6c, 6c, 6f, 2c, 20, 77, 6f, 72, 6c, 64, 21, a]), lpNumberOfBytesWritten:Some(46340c0), lpOverlapped:0)
Hello, world!
INFO kernel32/ExitProcess(uExitCode:0)
Those INFO logs are tracing places where one of my win32 APIs were called; the
Hello, world! is text printed by the .exe file.
Will this work going into the future? It's hard to say. Rosetta used to support 32-bit x86 but they dropped it. When linking there are ominous warnings like the following:
ld: warning: non-standard -pagezero_size is deprecated when targeting macOS 13.0 or later
I wouldn't be too surprised if Apple decided to drop x86 emulation altogether in some future MacOS release. On the other hand, I think Apple's "Game Porting Toolkit" (announced this year) relies on Wine which uses this technique. So I think I will clean this "rosetta" branch up and merge it in to retrowin32. If anything it was at least interesting to figure out.